
The Evolving Frontier of Future AI Demand
A review of my comprehensive FLOP demand outlook for investment decision-making.

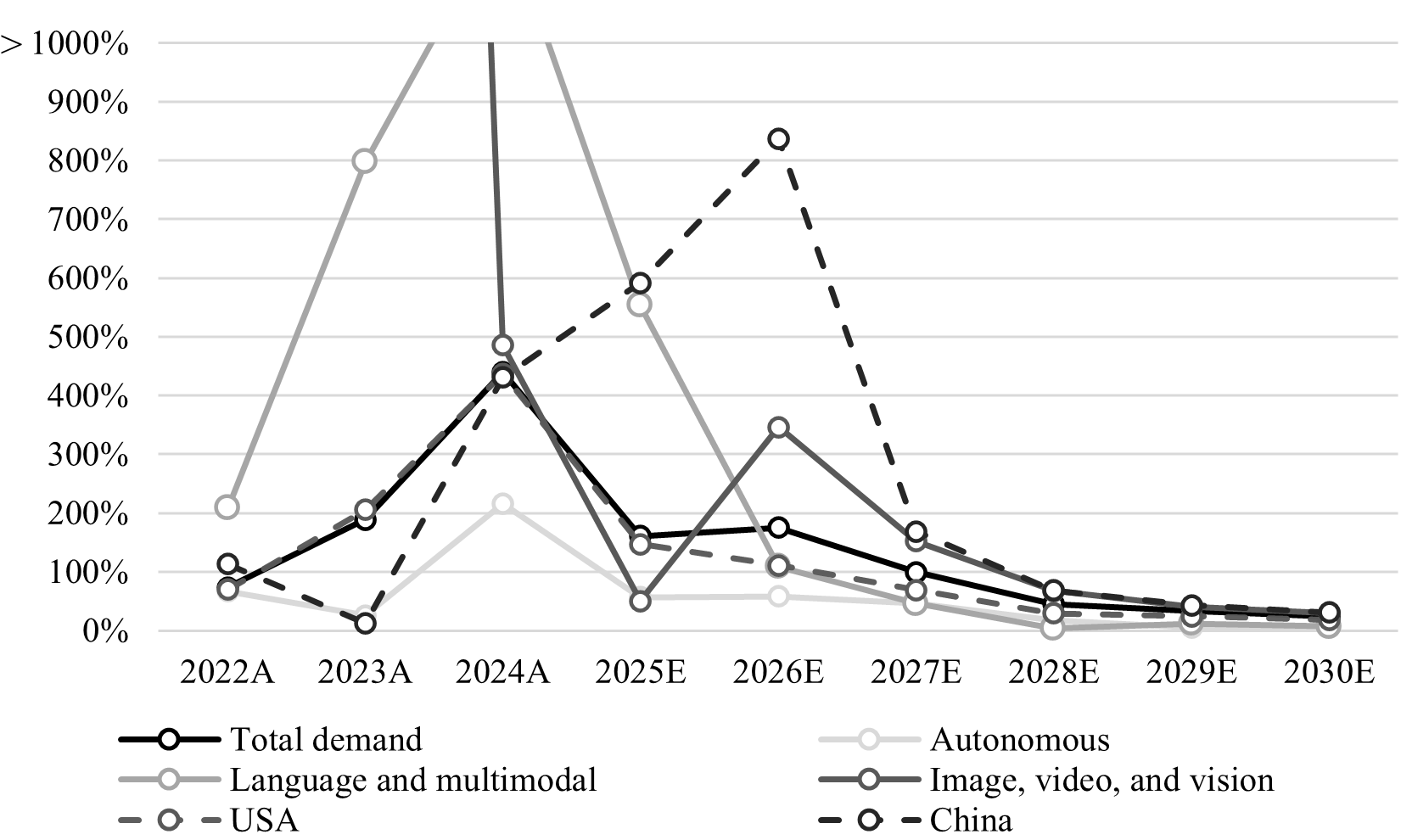
The near-term AI compute outlook appears supply-constrained. However, viable Chinese chips, credible U.S. competition, and edge utilization may offer respite to the exploding global compute requirements. To that end, I expect the 2026-2027 period to be an inflection point for AI demand. I forecast markedly higher FLOP requirements through 2027 and beyond, with China exceeding 50% of global demand by end-of-decade (up from only 6% in Q2 2025). Most importantly, I expect U.S. LLM demand to stabilize as user growth slows. Generative image, and more importantly video, as well as autonomy, will define the evolving frontier of future AI demand, driven by innovation in world models. I forecast global demand to grow at ~+79% p.a. (including +150% p.a. in China and +60% p.a. in the U.S.) through 2030. See Figure 1 for the updated AI compute demand forecast.
Investment Highlights
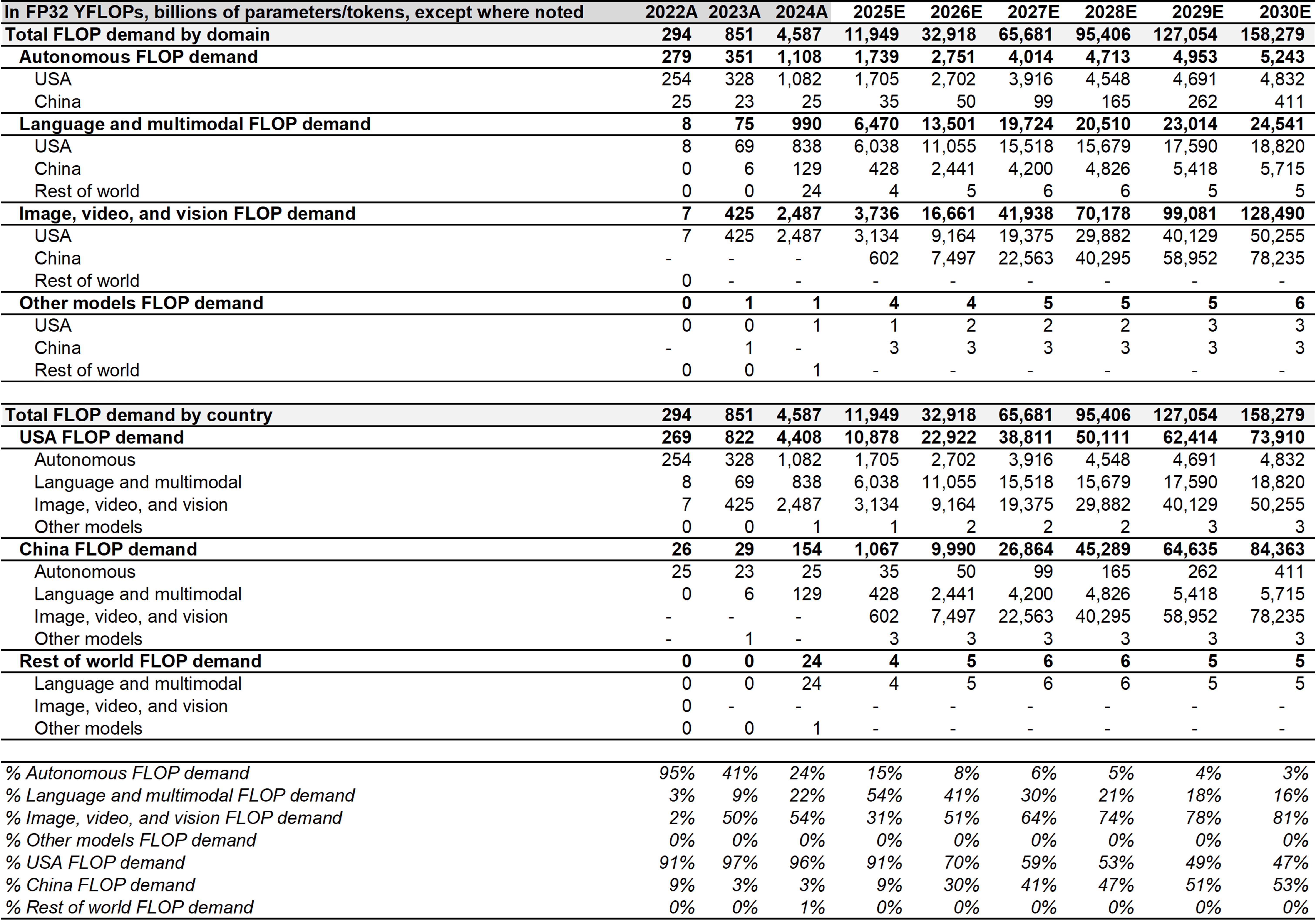
LLM growth slowing; image/video, autonomy accelerate. My revised 2025-2027 demand forecasts of 12.1 RonnaFLOPs (rFLOPs, or 10²⁷ floating-point operations), 32.9 rFLOPs, and 65.7 rFLOPs increased by an average of +53% p.a., driven by -18% p.a. lower LLM demand of 6.5 rFLOPs, 13.5 rFLOPs, and 19.7 rFLOPs, a very substantial +5.9x p.a. higher image and video demand of 3.9 rFLOPs, 16.7 rFLOPs, and 41.9 rFLOPs, and +33% p.a. higher autonomy demand of 1.7 rFLOPs, 2.8 rFLOPs, and 4.0 rFLOPs. Overall, I forecast image and video generation to exceed 50% of demand around the end of 2026.
China to overtake the U.S. I now forecast 2025-2027 U.S. demand of 10.9 rFLOPs, 22.9 rFLOPs, and 38.8 rFLOPs (representing mixed changes of -9%, +15%, and +39%) driven by slowing LLM growth. I expect 2025-2027 Chinese demand to reach 1.2 rFLOPs, 10.0 rFLOPs, and 26.9 rFLOPs driven by accelerating LLM growth (though, from a smaller base), and leadership in generative image and video. The Chinese investment in innovation (vs. the U.S. investment in user growth) enables shorter training cycles, lower capital intensity, and apparently more profitable unit economics. I expect Chinese compute demand to exceed U.S. compute demand by 2029, eventually reaching 53% of total global demand by 2030.
Chip competition + autonomy rollout = edge-first future. Nvidia appears poised to capitalize on the cloud-first AI opportunity. However, application AI is moving to the edge. For instance, world generation innovation means the vast majority (>75%) of forecast generative video demand represents rendering workloads, which occur on the edge today. A dual training cycle will be required to keep pace: a long-term, cloud-first regimen for heavier updates and a short-term, edge-first tuning program for rapid deployment. Ideally, the models adapt in real-time to direct user interaction, and Tesla is the leader there.
Figure 1 - Global AI Compute Demand Forecast
Global Demand Outlook
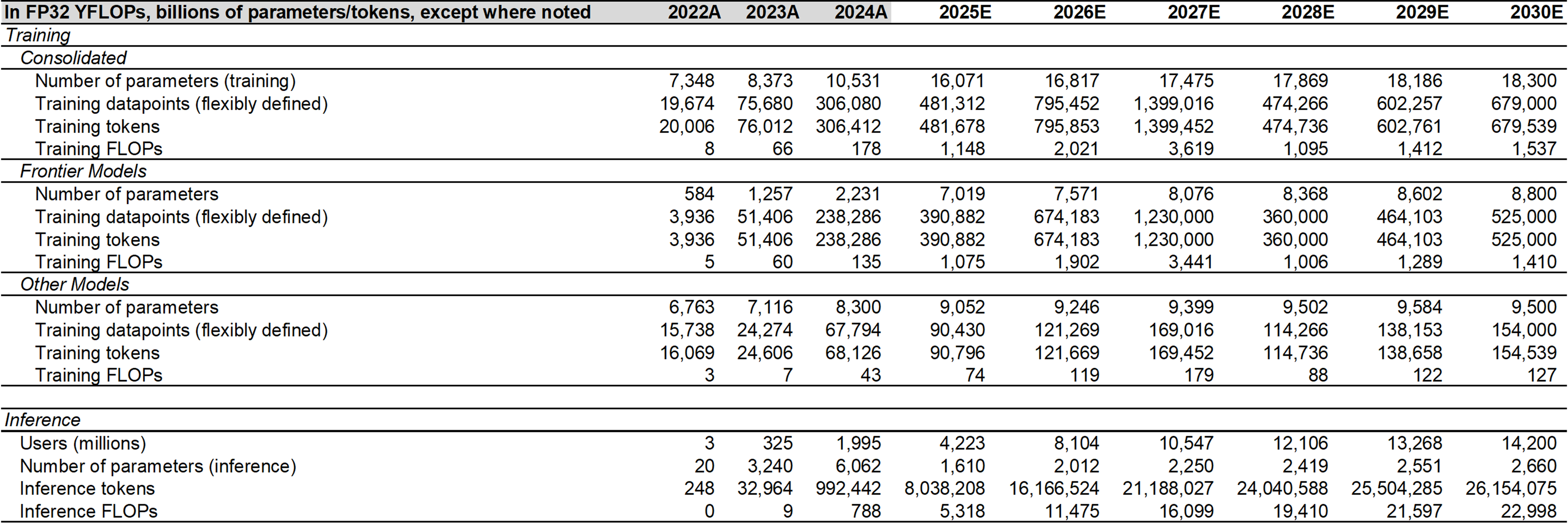
Mixed outlook for LLM growth. In 2022, OpenAI kicked off the race for user growth. I estimate the U.S. LLMs added 3M, 308M, and 1,404M system-wide users over the three annual periods spanning 2021-2024, primarily driven by OpenAI. In contrast, Chinese LLMs only gained nil, 14M, and 266M users over the same periods. Usage growth is a compounded function of user growth, as user intensity and query lengths increase. I expect global LLM growth to reach 5.5x for the 2024-2025 period, driven by moderating U.S. LLM user growth of 1.95x and China LLM user growth of 2.1x. Based on OpenAI CEO Sam Altman’s recent public statements, I estimate that OpenAI is operating at ~77% GPU utilization, representing capacity to absorb ~30% usage growth (which equals <30% user growth) before windfall compute (of approximately double current capacity) is expected to arrive in 2026. My updated 2025-2026 forecast for global LLM demand of 6.5 rFLOPs and 13.5 rFLOPs represents growth of 2.1x, suggesting that OpenAI will cede market share to competitors in the next year, after training compute requirements. Overall, my 2025-2027 global LLM compute demand forecast (including 19.7 rFLOPs for 2027) declined by -18% p.a., reflecting -23% p.a. lower U.S. LLM demand. See Figure 2.
Figure 2 - Global LLM Compute Demand Forecast
China is full-steam ahead. Although user adoption of Chinese LLMs is ~1 year behind comparable U.S. models, many have achieved comparable performance with 60% lower parameter activation. I forecast growing 2025-2028 Chinese FLOP demand of 1.1 rFLOPs, 10.3 rFLOPs, 26.9 rFLOPs, and 45.3 rFLOPs, representing 9%, 30%, 41%, and 47% of total global demand. China is now the undisputed leader in frontier AI (here) and innovation (which drives growth through use-case discovery and incremental, efficiency-driven usage capacity) appears to be accelerating (five SOTA updates to frontier AI have been released since June, with four coming from Chinese labs). In my view, this level of innovation was made possible by forgoing short-term user growth. User growth creates inference compute requirements that displace training compute, which is needed for innovation. Furthermore, innovation to create equally-performant models that consume fewer FLOPs lowers future training compute demands. I estimate the average Chinese frontier model is nearly half the size of equivalent U.S. models in Q2 2025, at full activation. Taken together, the Chinese labs have successfully achieved (and in some cases exceeded) performance-parity with U.S. SOTA, with far smaller models that can be trained in a fraction of the time, at a fraction of the cost. I forecast China exceeding 50% of total global compute demand by 2029, eventually reaching 53% by end-of-decade, primarily driven by rapid user growth. I anticipate growth of 6.9x and 9.4x over the 2024-2025 and 2025-2026 periods, tapering to 1.8x p.a. over the 2026-2030 period. I expect improving domestic chip manufacturing, early expansionary domestic economic growth, and the compounding adoption of Chinese application AI across the world to be key factors driving the heightened level of growth.
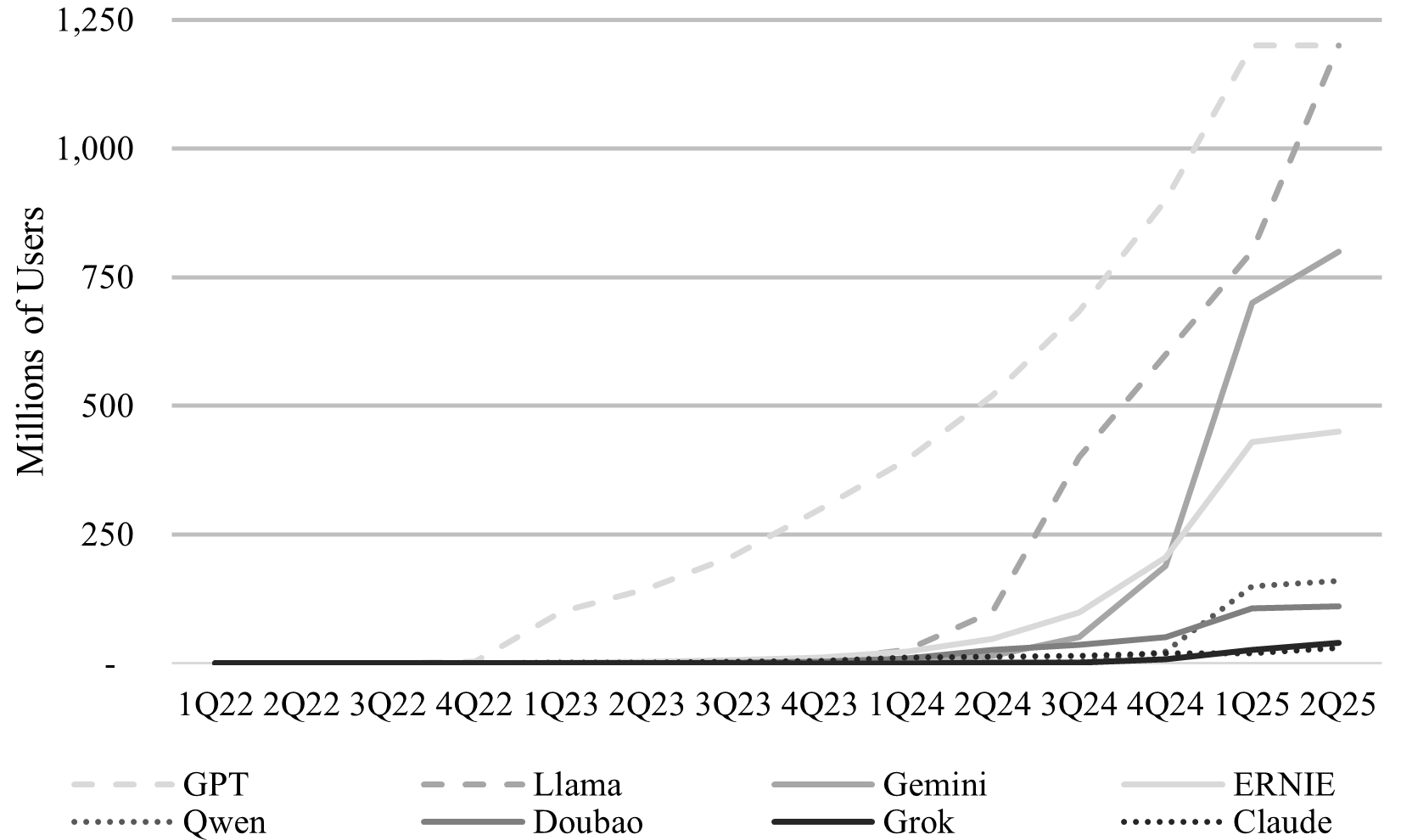
LLM user growth slowing. LLMs are currently too inference-inefficient to scale without a surrogate compute supplier, primarily due to structural differences in model architecture. While broad adoption of MoE and routing innovations have improved inference efficiencies, many labs appear compute-constrained, driven by markedly higher user demand for the newest-gen models. Based on the latest publicly-available data, I estimate ChatGPT, Gemini, and Grok have surpassed 1.2B, 0.8B, and 40M MAUs, respectively (+2.3x, +58.2x, and +105.8x YoY). However, growth appears to be stagnating (only +0%, +14%, and +55% QoQ). See Figure 3. The massive inference compute requirements are cannibalizing training compute for model innovation, which pushes many labs to pursue less compute-intensive differentiation like context and memory, multimodal, and personalization, as models commoditize. I expect the crowding out of cloud computing supply to compel LLMs to push inference to the edge, in an effort to harvest margin. The existing suppliers of high-performance edge GPU compute (for phones, laptops, etc.) appear well-positioned to benefit.
Figure 3 - Frontier Model Users Over Time
Distribution is king. Google is reportedly in talks with Apple to power Siri with Gemini (Apple had previously approached OpenAI and Anthropic). In a world of near-feature-parity, users will seek the 1) cheapest and 2) most available models. In my view, Amazon Nova (AWS), Gemini (Google), Grok (X), Llama (Facebook, Instagram, WhatsApp), Doubao (TikTok, Douyin), ERNIE (Baidu), Hunyuan (WeChat), and Qwen (DingTalk, Alipay, Taobao) appear poised to leverage built-in channels for accelerated user growth (whereas the 6 other frontier labs must partner or grow organically).
World generation adds material incremental demand. Tencent (HunyuanWorld-1.0) and Google DeepMind (Genie 3) have released compelling world generation models. A “world” refers to a simulated 3D environment (think Minecraft or Fortnite), with dynamic interactive objects, that is navigable by the user. World generation refers to the process of leveraging AI systems to generate such worlds. Tencent and Google respectively aim to apply the technology to gaming and AR/VR experiences, as well as animation. In my view, two domains will see the greatest marginal impact:
Image and video generation. I forecast incremental 2025-2027 compute demand of 0.6 rFLOPs, 13.3 rFLOPs, and 38.4 rFLOPs attributable to world generation, or +1.2x, +4.9x, and +11.7x above my prior forecast, driven primarily by growing usage for higher-quality generative image and video. This includes my maiden forecast for Chinese image and video FLOP demand. See Figure 4. To date, image and video generation have faced two challenges: spatial awareness and efficiency. Models struggle to learn and reproduce depth and, more importantly, pixel generation is both inefficient (a standard 4K feature-film requires ~4.6 quadrillion pixels) and inaccurate (an unrealistically low error rate of only 0.5% implies ~27s of faulty video). World generation improves both dimensions. The method involves training a projection model to place objects in 3D space, which is easier to train, less costly to generate, and produces higher-fidelity visuals. Most importantly, compatibility with rendering software (like Unreal Engine) re-casts inference as a rendering problem, which edge GPUs are already well-equipped for.
Figure 4 - China Image, Video, and Vision Compute Demand Forecast
Autonomous simulation. Famously, Tesla has been partially training FSD on simulated miles since at least 2021, using proprietary software. One major challenge in autonomy (robotics, vehicles, drones, etc.) is the cost-effective design and creation of physical environments for agent interaction. Generated worlds could potentially simulate 1) better training environments 2) at lower cost. For instance, a fire-fighting robot could train on many more generated emergencies than can be feasibly recreated in the real world. I await material public data on the leading robotics and autonomy models before including a forecast in my base case.
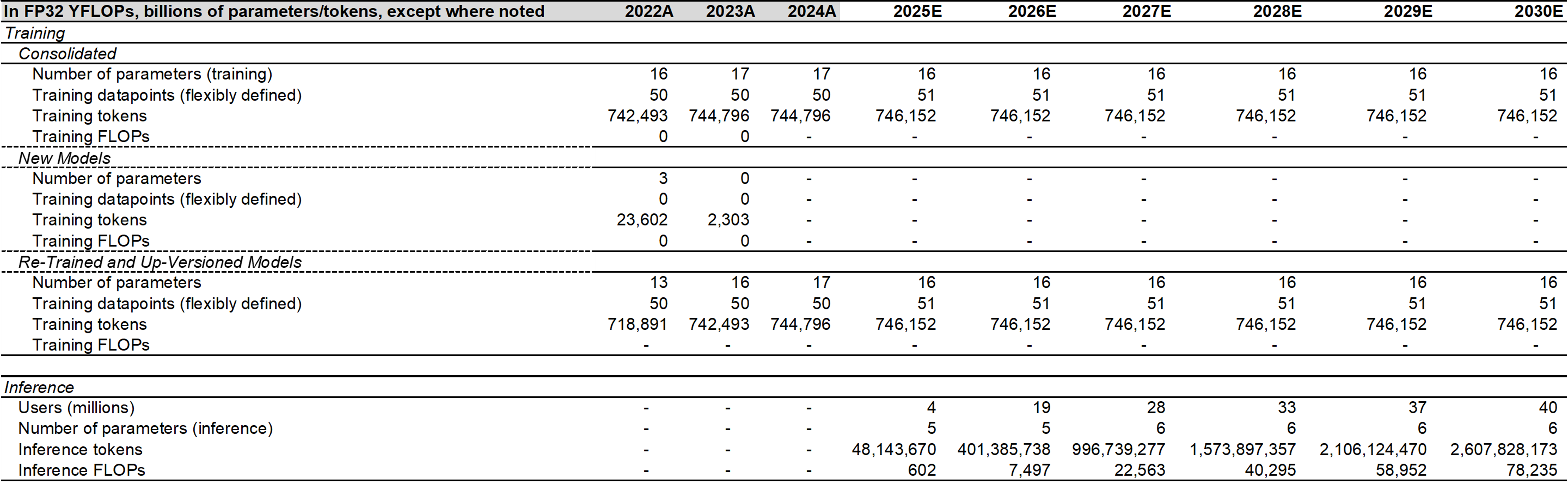
Tesla pulls ahead in autonomy. AV training unexpectedly slowed through H1 2025, primarily driven by slower-than-anticipated GPU capacity installations (Tesla only released 8 notable software updates, compared to 28 in H2 2024). Robotaxi programs continue to expand in the U.S. and globally (primarily Europe for Tesla and Japan for Waymo). Cruise is also reportedly weighing a Japan launch for 2026. Waymo is the current leader in terms of total deployments, but Tesla is not far behind. In my view, Tesla’s vertical integration represents a structural advantage for both distribution and training. I estimate that Tesla accounted for a substantial 31%, 31%, and 23% of total autonomous demand, autonomous training demand, and total aggregate training demand in Q2 2025. See Figure 5 for a stratified ridership profile. The model-only players (Apollo Go, Pony.ai, Waymo, WeRide, Waymo) have partnered with distribution providers (primarily Uber). Distribution remains the primary challenge for most, as regulators look to rideshare operators for safety amid the global rollout. Compute supply security also remains a top concern. I now forecast growing 2025-2027 global autonomy compute demand of 1.7 rFLOPs, 2.8 rFLOPs, 4.0 rFLOPs, representing an increase of +33% p.a. compared to my prior forecast, driven by modestly increased supply. My base-case forecast excludes most map-based models. See Figure 6 for the global autonomy compute demand forecast.
Figure 5 - Daily AV Ridership Profile by Modality
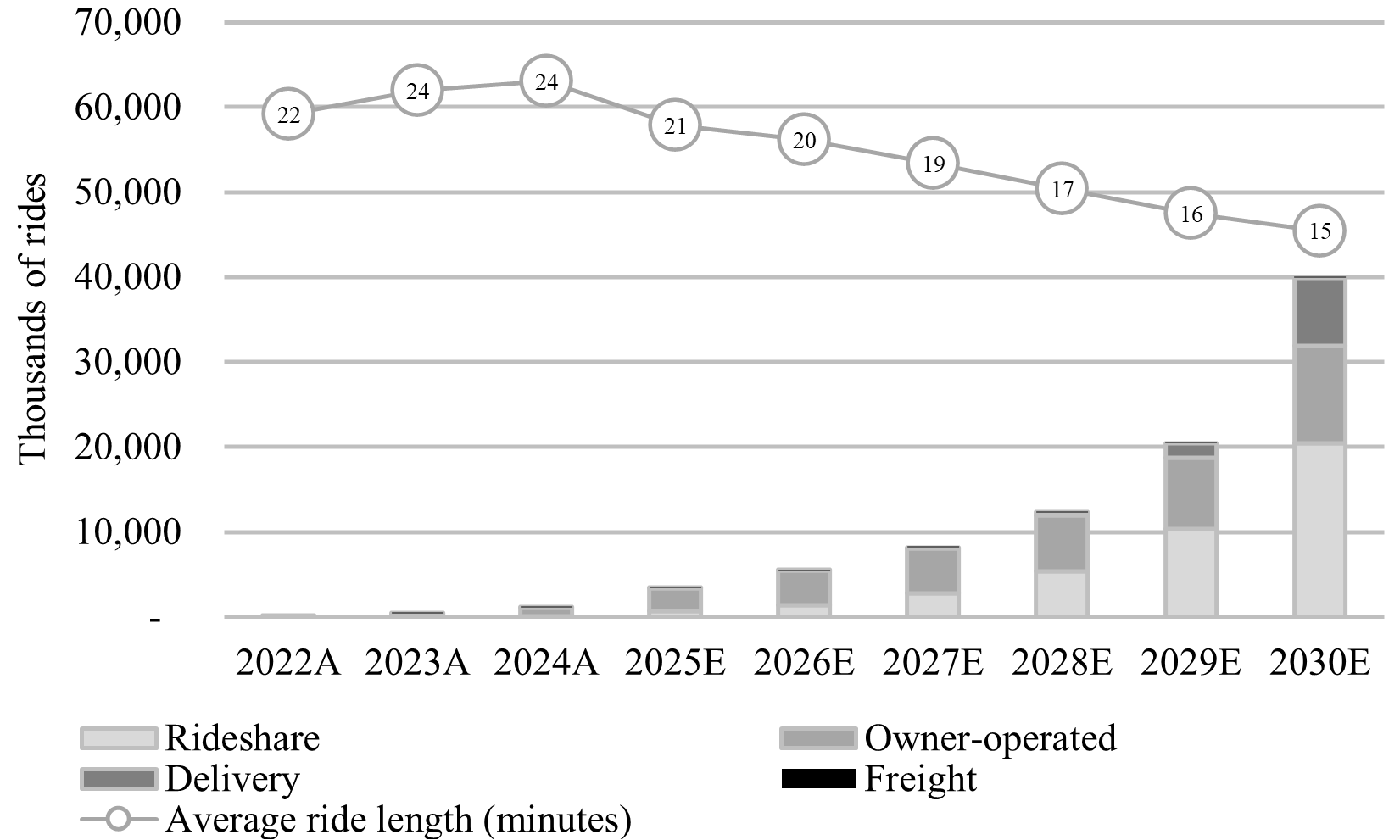
Figure 6 - Global Autonomy Compute Demand Forecast
China lags AVs, leads freight; robotics represent upside. The Chinese AV market is comprised of at least five credible players (Pony.ai, WeRide, Apollo Go, DeepRoute.ai, and Didi), making it more structurally competitive than the U.S. market, which only has two truly credible players (Tesla and Waymo; with Uber offering distribution for AV partners). Four of the five players (ex. Didi) have already expanded operations to the U.S., Europe, and the Middle East, in addition to operating domestically within China. Tesla’s Chinese Robotaxi regulatory approval is reportedly delayed due to concerns over the handling of domestic data, which I view as a stall tactic to allow for the development of more mature AV technology (all Chinese AVs still rely on LiDAR). I now forecast 2025-2027 Chinese AV compute demand of 35 YottaFLOPs (yFLOPs, or 10²⁴ FLOPs), 50 yFLOPs, and 99 yFLOPs (-1% p.a. compared to my prior forecast), representing a minor 2% p.a. of global AV demand. Notably, China leads in autonomous freight, with Pony.ai and Inceptio now operating regular short- and long-haul routes, respectively, across major Chinese cities and arteries. In contrast, Aurora and Kodiak remain restricted to the prolific Houston-Dallas corridor. Tesla is expected to begin ramping up Semi production by end-of-year.
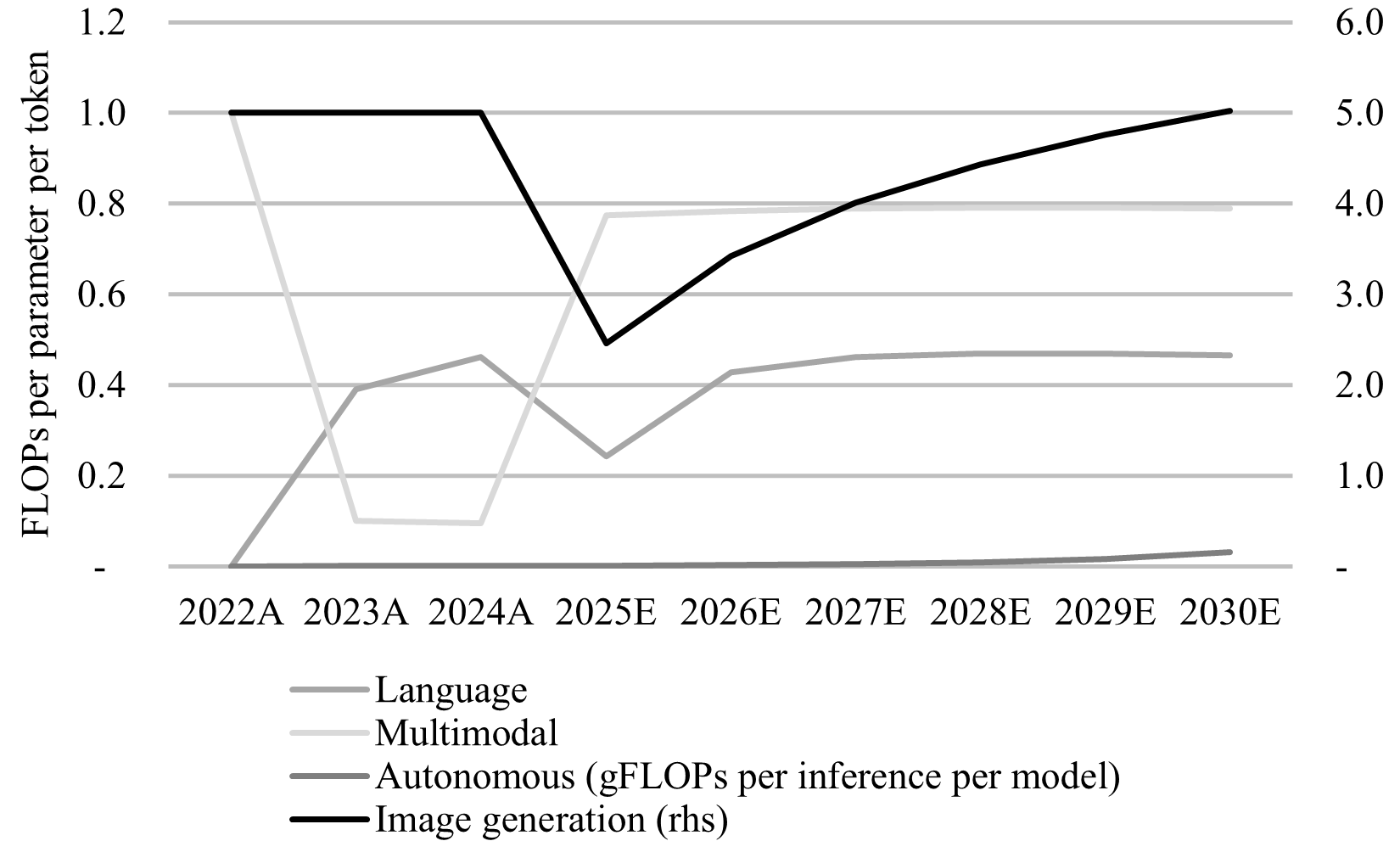
Autonomy remains structurally more scalable than LLMs. Although LLMs have quickly captured user growth, many SOTA models are still high-parameter-count monoliths. Expert routing and load balancing techniques have decreased parameter activation resulting in less cost, but unit economics remain unattractive. In contrast, autonomous models are trained with a multi-step, multi-model approach. For example, Tesla trains many, specialized models for different self-driving tasks (vision, object identification, routing, control, etc.). At inference time, the models activate at different times as needed, resulting in lower overall inference costs. LLMs are typically trained end-to-end and require the entire, massive model to activate for inference. World generation models are an important innovation for image and video generation because they enable the same efficiencies as AV models (whereas diffusion models appear closer to LLMs in terms of efficiency). See Figure 7 for a comparison of cross-domain inference efficiency.
Figure 7 - Time-Series Cross-Domain Inference Efficiency
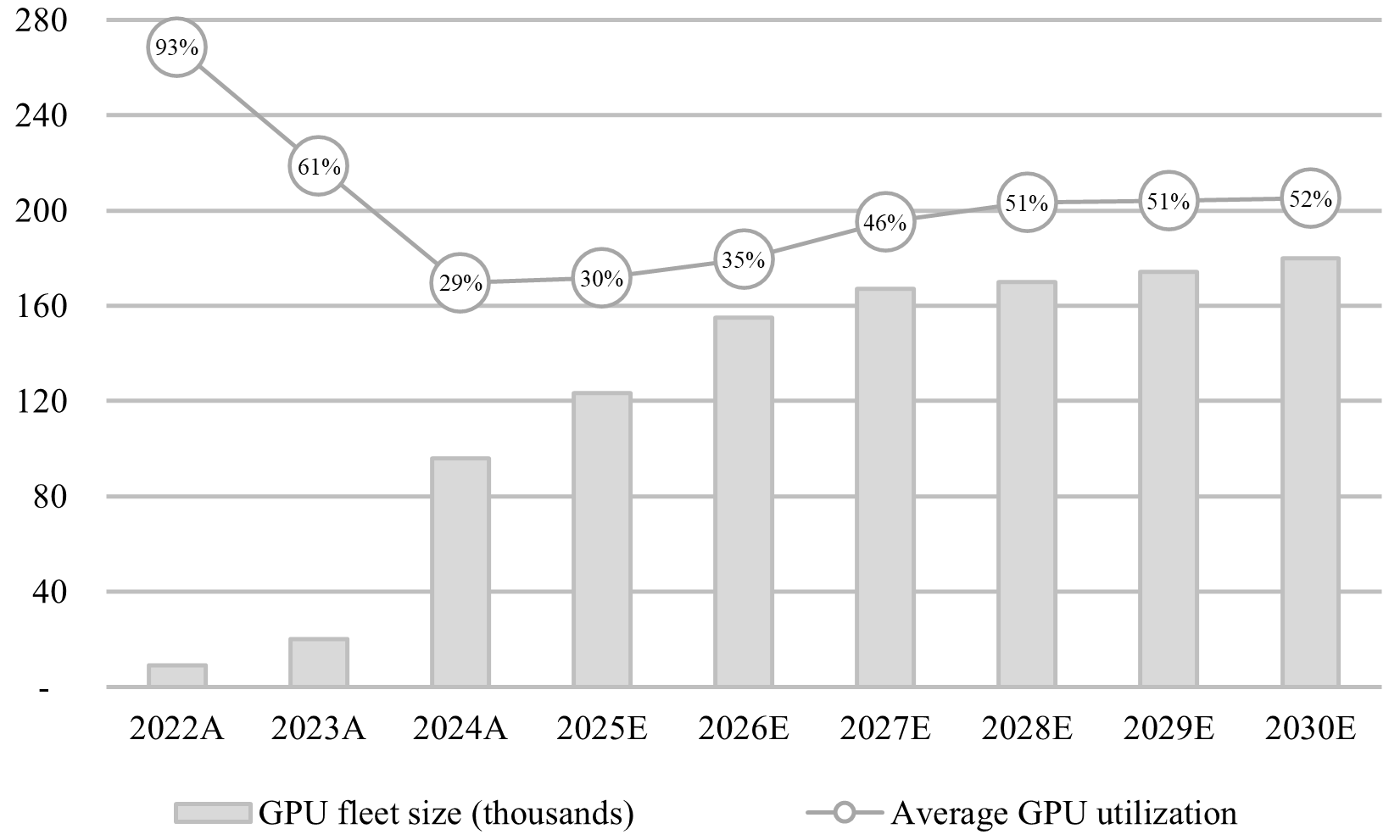
Near-term bottlenecks mostly unresolved. AV consolidation has already been underway for nearly a decade (GM acquired Cruise in 2016), largely driven by compute requirements. While Tesla expects to achieve >120 thousand H100e GPUs by Q3 2025 (and has already increased capacity to ~110 thousand H100e GPUs in Q2 2025, up from ~90 thousand), competitors largely rely on cloud compute. The LLMs are expected to pivot to cost containment and potentially supply incremental compute to the market (of which AVs comprise the primary buyers). I now forecast GPU fleet requirements reaching 180 thousand chips at 1.8 pFLOPS per GPU by the end of the decade (+38% compared to my prior forecast of 130 thousand chips at 1.7 pFLOPS per GPU), up +54% from 117 thousand chips today at 1.9 pFLOPS per GPU. See Figure 8.
Figure 8 - Autonomous GPU Fleet Profile
Is LiDAR necessary? All in, I estimate that LiDAR costs ~US$2,500 (or ~5% of a hypothetical US$50,000 MSRP vehicle) more per vehicle for ~186M fewer up-front training hours (or ~1,400 yFLOPs, representing a -80% decrease in training volume). In my view, there are three potential future scenarios for LiDAR:
(Base case) LiDAR-supported models achieve performance parity with video-only. Absent a potential regulatory mandate for fallback LiDAR, additional hardware costs would compress industry-wide margins. I expect OEMs to absorb incremental cost, especially for the mass market models needed to achieve scale. In fact, elevated autonomous revenues could even justify lower average MSRPs.
LiDAR-supported models underperform and video-only becomes the standard. LiDAR-reliant players must either invest the massive dollars, miles, and compute for ~5 years of re-training to remain compliant; or else exit the AV business.
LiDAR-supported models outperform and become the standard. Video-only players could achieve compliance with minimal retraining (LiDAR training is less intensive). Moreover, the high cost and long training timelines needed for LiDAR-reliant models to transition to video-only justifies the continued pursuit of a video-only model with superior performance.
Upside to global demand. Several major model categories have shown negligible inference uptake (as a proportion of total demand), including biology, gaming, medicine, voice, and robotics. Although research appears to comprise the majority of near-term compute requirements for these domains, significant advancements could lift the medium-to-long-term outlook. Training demand tends to be a leading indicator for inference uptake, as models hit use-case milestones and research funding increases. Any progress on user-adoption would create material upside to my outlook for the future of AI demand.
Inflection in demand growth expected next year. I estimate global demand grew by +5.4x in 2024, up from only +2.9x in 2023 and 1.7x in 2022. In 2025, I estimate growth of -21% QoQ in Q2 (or +11% YoY), driven by lower U.S. LLM parameter activation rates for inference, offset by strong year-on-year user growth. This compares to -15% QoQ in Q1 (or +90% YoY) and +20% QoQ in Q4 2024 (or +347% YoY). Demand growth over the 2018-2022 period of 260.0x from 8 yFLOPs to 294 yFLOPs was driven primarily by Tesla’s AV training and early usage for Baidu’s ERNIE LLM, I forecast demand growth of 2.6x in 2025, rising to 2.8x in 2026, and continuing at 2.0x, 1.5x, 1.3x, and 1.2x for 2027-2030. See Figure 9.
Figure 9 - Global Compute Demand Growth Profile
Not all AI capex is created equal. I have reviewed the investment economics for Meta Superintelligence Labs, OpenAI, and Anthropic in Figure 10. Cumulative pro-forma capex for the three LLM ventures is estimated at US$528B, US$270B, and US$14B respectively. Assuming a 12% cost of capital and 5% p.a. terminal growth, the labs must achieve ~US$76B, ~US$45B, and ~US$4B of free cash flow by 2035, respectively, representing 48%, 39%, and 2% of expected 2026 burn, to hit a 15% IRR. This analysis optimistically assumes no incremental future capex. Overall, Anthropic appears to have the best chance of achieving reasonable investment returns, while OpenAI has the worst chance. It remains a standing question whether future LLM demand is available at attractive enough margins to justify the capital intensity, and whether installed capacity can even service that level of demand.
Figure 10 - Breakeven Terminal FCF Analysis of Select AI Labs

Biology and medicine. Biology and medicine continue to benefit from the latest LLM advancements. Still, the leading models face four major obstacles:
Imbalanced outcomes. In medicine, prediction inaccuracies have serious consequences and model precision still falls short.
Incomplete data. Structured data for >95% of the protein universe doesn’t exist. Health data is also poorly structured and largely protected by HIPAA and GDPR.
Biology is not a language. Transformers don’t learn biological context by default and, unlike language, biological data encodes little sequential context. Labelled data is in relatively short supply.
Regulations. Health regulations are not built for rapid tech adoption. For example, models in the U.S. may still be treated as “medical devices”, which go through multiple approval stages and carry potential malpractice liability.
Despite these challenges, the compelling economics of healthcare (which accounts for nearly $1 for every $5 of developed-world GDP) and growing corporate sponsorship support further innovation. I forecast other categories of models, including biology and medicine, to grow from 1 yFLOP of demand in 2024 to 6 yFLOPs of demand in 2030 (+30% p.a.).
Final Thoughts
The near-term AI compute outlook appears supply-constrained. However, viable Chinese chips, credible U.S. competition, and edge utilization may offer respite to the exploding global compute requirements. Overall, LLM demand growth appears to be slowing, as user growth stagnates and frontier labs increasingly focus on model efficiency. I anticipate world generation to drive meaningful innovation in image and video generation, as well as autonomy. The Chinese investment in innovation has largely paid off in the form of shorter training cycles, lower capital intensity, and apparently more profitable unit economics than U.S. counterpart labs. Finally, chip competition and the global rollout of autonomy appear to be pushing compute to the edge. A dual training cycle will be required to keep pace: a long-term, cloud-first regimen for heavier updates and a short-term, edge-first tuning program for rapid deployment. Ideally, the models adapt in real-time to direct user interaction, and Tesla is the leader there.